
In one of my last posts I hinted to the fact that JAGS could be used for simulation studies. Let’s have a look! So basically simulation studies are very useful if one wants to check if a model one is developing makes sense. The main aim is to assess, if the parameters one has plugged into a data simulation process based on the model could be reasonably recovered by an estimation process. In JAGS it is possible to simulate data given a model and a set of known parameters and to estimate the parameters given the model and the simulated data set. For today’s example I have chosen a simple psychometric latent variable measurement model from classical test theory, which is very well understood and can be easily estimated with most software capable of latent variable modeling. Here it is:


 .
.




The basic idea is that a latent trait  is measured by three items (
is measured by three items ( to
to  ) with different difficulties (
) with different difficulties ( to
to  , different loadings (
, different loadings ( and
and  ) and different measurement error variances (
) and different measurement error variances ( to
to  ). For identification reasons, the loading of item 3 is set to 1. Furher the variance of the trait (
). For identification reasons, the loading of item 3 is set to 1. Furher the variance of the trait ( ) has to be estimated from data.
) has to be estimated from data.
For simulating data with JAGs we have to specify a data block. The model specification is straight forward, note that we have to hand over the true parameters to JAGS, for example with an R script. This is pretty handy because one could design a thorough simulation study for different sample size and parameter combinations. The estimation part has to be specfied in a model block.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | #Simulation data{ for(i in 1:n) { y1[i]~dnorm(mu1.true[i], tau.y1.true); y2[i]~dnorm(mu2.true[i], tau.y2.true); y3[i]~dnorm(mu3.true[i], tau.y3.true); mu1.true[i]<-lambda1.true*eta.true[i]+beta1.true mu2.true[i]<-lambda2.true*eta.true[i]+beta2.true mu3.true[i]<-eta.true[i]+beta3.true } tau.y1.true<-pow(sigma.y1.true, -2); tau.y2.true<-pow(sigma.y2.true, -2); tau.y3.true<-pow(sigma.y3.true, -2); } # Estimation model{ for(i in 1:n) { y1[i]~dnorm(mu1[i], tau.y1); y2[i]~dnorm(mu2[i], tau.y2); y3[i]~dnorm(mu3[i], tau.y3); mu1[i]<-lambda1*eta[i]+beta1 mu2[i]<-lambda2*eta[i]+beta2 mu3[i]<-eta[i]+beta3 } for(i in 1:n) { eta[i]~dnorm(0,tau.eta); } # Priors for the loadings lambda1~dnorm(0,1.0E-3) lambda2~dnorm(0,1.0E-3) bias_lambda1<-lambda1-lambda1.true # Priors for the easiness parameters beta1~dnorm(0,1.0E-3) beta2~dnorm(0,1.0E-3) beta3~dnorm(0,1.0E-3) bias_beta1<-beta1-beta1.true # Hyperprior for latent trait distribution tau.eta<-pow(sigma.eta,-2) sigma.eta~dunif(0,10) # Priors for the measurement errors tau.y1<-pow(sigma.y1, -2); tau.y2<-pow(sigma.y2, -2); tau.y3<-pow(sigma.y3, -2); sigma.y1~dunif(0,10); sigma.y2~dunif(0,10); sigma.y3~dunif(0,10); } |
This may look a bit daunting, but it really took only 15 minutes to set that up.
The simulation is controlled by an R script, which hands over the true parameters to JAGS:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | library(R2jags) library(mcmcplots) n=500 # number of subjects # generate 'true' latent trait values eta.true<-rnorm(n, 0, 4) # generate 'true' factor loadings lambda1.true=1 lambda2.true=0.5 beta1.true=1 beta2.true=2 beta3.true=3 # generate 'true' error standard deviations sigma.y1.true=1 sigma.y2.true=0.5 sigma.y3.true=0.75 data<-list("n", "eta.true", "lambda1.true", "lambda2.true", "sigma.y1.true", "sigma.y2.true", "sigma.y3.true", "beta1.true", "beta2.true", "beta3.true") parameters<-c("lambda1","lambda2", "sigma.eta", "sigma.y1", "sigma.y2", "sigma.y3", "beta1", "beta2", "beta3", "bias_beta1") output<-jags.parallel(data, inits= NULL, parameters, model.file="simple_1f.txt",n.chains=2, n.iter=35000, n.burnin=30000) attach.jags(output) denplot(output) traplot(output) plot(output) |
If we inspect the posterior densities based on one dataset with sample size 500 we see that we pretty much hit the spot. That is, all posterior densities are covering the generating true parameters.
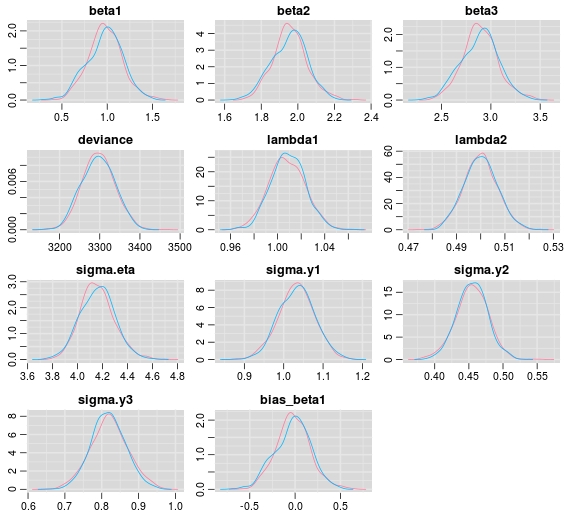
Please note that in the estimation code a posterior density for the difference between the data generating parameter and its’ samples from the posterior is specified. The zero is very well covered, but keep in mind that this is based only on one dataset. To replicate a more traditional approach to bias, a viable route could be to simulate several hundreds of datasets and to record for example the posterior mean for each parameter and data set to assess bias.
As always, keep in mind that this is pretty experimental code and estimating latent variable models with JAGS is not very well explored yet as far as I know. However, the main point of this post was to show how JAGS could be used in combination with R to run simulation studies in a probabilistic graphical framework. Should work for multilevel models or generalized mixed models too.
Edit: I just stumbled about this recent blog post by Robert Grand. So stan should work too. Interesting!
Pingback: Simulate data in JAGS/r2jags | Codeba